Container networking
Before I start, I must point out that I’m not an expert on this topic. Everything I’ll write here I learned from my own research and tried to understand what is going on.
If you find any mistakes, please reach out to me! :)
What are Containers?
Have you ever wondered what happens when you run a container using a
simple docker run -d -p 8080:80 nginx?
What is the magic that allows us to reach that nginx server?
Containers are a complex topic, and I can’t explain everything in one blog post. However, to understand container networking, we need to cover some basics.
Containers are simply processes running on the host machine. Lets take a look at a quick example.
┌──(ales㉿kali)-[~]
└─$ docker run -d alpine sleep 50
2fc8767bb3b7b1af09fb12f4bc0d9189c8ffe3e7240fcf9ee20738844a1ac503
┌──(ales㉿kali)-[~]
└─$ ps -fC sleep
UID PID PPID C STIME TTY TIME CMD
root 2944 2923 0 22:37 ? 00:00:00 sleep 50
As you can see from the above output the container we’ve created is really just a process running on the host machine.
So what makes them different from other processes?
- Isolation: Containers shouldn’t access global resources (processes, mounts, etc.).
- Limited resources: Containers shouldn’t be able to grow unchecked, as that might cause denial of service on the host machine.
- Self-Containment: Containers should include all dependencies they need.
Namespaces
What gives containers isolation are Linux namespaces. A namespace wraps a global system resource in an abstraction that makes it appear to the processes within the namespace that they have their own isolated instance of the global resource.
Whenever a process spawns, it inherits its parent namespaces. That is why normally all processes see the same global resources.
There are various types of namespaces: Cgroup, IPC, Network, Mount, PID, Time, User and UTS.
In scope of this post I’ll focus on network namespaces as the title suggests.
What happens when container is created network wise?
Once a process is created and put in a different network namespace, it gets a completely new network stack. This includes network interfaces and routing tables.
To make it useful, it needs to connect to the host, because by default, a new network namespace cannot be reached nor can it communicate with the outside world.
This connection is made using virtual ethernet interface devices, which always come in pairs. One end is plugged into the Docker bridge interface, and the other end is plugged into the newly created network namespace.
To also explore how container to container networking works let’s add another container to the mix.
┌──(ales㉿kali)-[~]
└─$ docker run -d -p 8888:80 --name container-a nginx
4a218a420594c7e8053b53f719f11a57da564b6a1026d8f673af661b29a1646e
┌──(ales㉿kali)-[~]
└─$ docker run -d -p 9999:80 --name container-b nginx
8f616dc2c9996903e1fdd70e5004ec23ed240fd331bfa5e804e45bd3f5bd4805
So what we are looking at looks something like this:
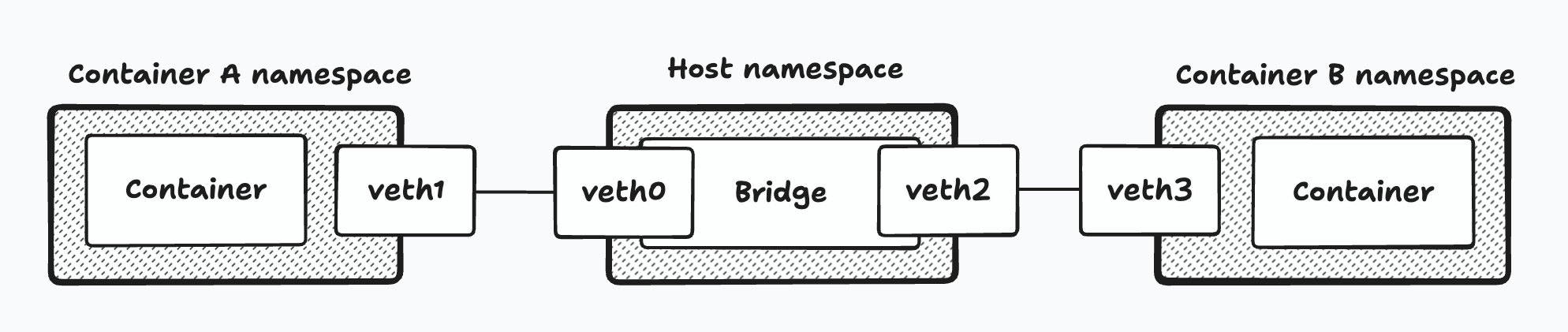
And to prove virtual ethernet interfaces were created:
┌──(ales㉿kali)-[~]
└─$ ip a
...
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:20:48:14:c2 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:20ff:fe48:14c2/64 scope link proto kernel_ll
valid_lft forever preferred_lft forever
10: vethbe33716@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 8e:03:c9:5b:41:5c brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::8c03:c9ff:fe5b:415c/64 scope link proto kernel_ll
valid_lft forever preferred_lft forever
12: veth336d0b1@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 6e:d8:de:4c:9e:bd brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::6cd8:deff:fe4c:9ebd/64 scope link proto kernel_ll
valid_lft forever preferred_lft forever
We see that vethbe33716 and veth336d0b1 were added.
Now to verify that interfaces were added to container as well:
┌──(ales㉿kali)-[~]
└─$ docker exec container-a ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
9: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
eth0 was added to the container! As you can see this interface isn’t named at those two above, this is probably because if an attacker gets access to the container, we don’t want to expose information that we are inside of a container (even though there are multiple ways to figure this out).
How do containers communicate with each other?
Because Docker bridge interface is basically a virtual switch it all happens using ARP (Address Resolution Protocol).
So how does this look like in practice:
- Container A wants to talk to Container B (172.17.0.4)
- Because it’s on the same subnet as he is it sends out ARP request broadcast: Who has IP 172.17.0.4?
- Bridge catches it and it responds with the MAC address of Container B
- Container A can now encapsulate the data in Ethernet frames using the MAC address and send it directly to Container B.
┌──(ales㉿kali)-[~]
└─$ docker exec -it container-a bash
root@4a218a420594:/# curl http://172.17.0.4
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
....
</html>
root@4a218a420594:/# ip neigh
172.17.0.4 dev eth0 lladdr 02:42:ac:11:00:04 REACHABLE
172.17.0.1 dev eth0 lladdr 02:42:20:48:14:c2 STALE
The neighbor table, which can be viewed and managed using the ip neigh command, stores IP-to-MAC address mappings. When ARP resolves an IP address to a MAC address, this mapping is stored in the neighbor table.
How can we communicate with our containers?
From docker host
We’ve published 8888 and 9999 for this right?
Yeah but that isn’t the only way, it turns out we don’t need port publishing to communicate with containers.
Lets inspect one of the containers:
┌──(ales㉿kali)-[~]
└─$ docker inspect container-a
[
{
....
"NetworkSettings": {
...
"IPAddress": "172.17.0.3",
The interesting part here is the IPAddress. If we create a request towards that nginx instance:
┌──(ales㉿kali)-[~]
└─$ curl http://172.17.0.3
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
</html>
We get a response! It turns out that port publishing isn’t really necessary if we want to connect to our containers from the Docker host. But it does help our sanity, else we would have to track IPs of containers all the time.
So how does port publishing even work?
Lets revisit the first command we ran:
docker run docker run -d -p 8888:80 --name container-a nginx
-p 8888:80 indicates we want to publish port 8888 on all
interfaces to point to the port 80 of newly created container.
To get all interfaces we can use ip a and exclude those without IP address.
┌──(ales㉿kali)-[~]
└─$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 8a:b4:20:b1:e5:cb brd ff:ff:ff:ff:ff:ff
inet 192.168.64.2/24 brd 192.168.64.255 scope global dynamic eth0
valid_lft 74289sec preferred_lft 74289sec
inet6 fdf8:2e7e:8a09:6e7a:88b4:20ff:feb1:e5cb/64 scope global dynamic mngtmpaddr proto kernel_ra
valid_lft 2591984sec preferred_lft 604784sec
inet6 fe80::88b4:20ff:feb1:e5cb/64 scope link proto kernel_ll
valid_lft forever preferred_lft forever
...
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:20:48:14:c2 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:20ff:fe48:14c2/64 scope link proto kernel_ll
valid_lft forever preferred_lft forever
...
Meaning we should be able to connect to our container using lo, eth0 and docker0 interfaces.
┌──(ales㉿kali)-[~]
└─$ curl -I 127.0.0.1:8888
HTTP/1.1 200 OK
...
┌──(ales㉿kali)-[~]
└─$ curl -I 192.168.64.2:8888
HTTP/1.1 200 OK
...
┌──(ales㉿kali)-[~]
└─$ curl -I 172.17.0.1:8888
HTTP/1.1 200 OK
...
Which we can!
This functionality is implemented using: iptables and docker-proxy.
iptables
Lets inspect iptables. We are interested in the OUTPUT chain inside NAT table. The OUTPUT chain is used to modify packets that are generated by the local system.
┌──(ales㉿kali)-[~]
└─$ sudo iptables -L -t nat
[sudo] password for ales:
...
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
DOCKER all -- anywhere !127.0.0.0/8 ADDRTYPE match dst-type LOCAL
Chain DOCKER (2 references)
target prot opt source destination
RETURN all -- anywhere anywhere
RETURN all -- anywhere anywhere
DNAT tcp -- anywhere anywhere tcp dpt:8888 to:172.17.0.3:80
As we can see Docker adds a new rule to the output chain that
matches all local addresses except !127.0.0.0/8 range. Inside this rule
it checks if destination port is 8888 and forwards traffic to 172.17.0.3:80
which is our container.
If we return to our scenario, this rule handles eth0 and docker0 interfaces.
But how does the 127.0.0.1 still work even though it’s excluded from the rule?
Why is it even excluded?
docker-proxy
It turns out that the 127.0.0.0/8 range is special. From RFC:
127.0.0.0/8 - This block is assigned for use as the Internet host
loopback address. A datagram sent by a higher-level protocol to an
address anywhere within this block loops back inside the host. This
is ordinarily implemented using only 127.0.0.1/32 for loopback. As
described in [RFC1122], Section 3.2.1.3, addresses within the entire
127.0.0.0/8 block do not legitimately appear on any network anywhere.
Therefore, it’s not possible to apply NAT rules to packets sent to this range. This is why Docker creates a userland proxy for each of the published ports, which forwards traffic to the containers.
To verify this we can inspect open ports and processes that own them using ss -tunlp.
┌──(ales㉿kali)-[~]
└─$ sudo ss -tunlp
[sudo] password for ales:
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
tcp LISTEN 0 4096 0.0.0.0:9999 0.0.0.0:* users:(("docker-proxy",pid=15882,fd=4))
tcp LISTEN 0 4096 0.0.0.0:8888 0.0.0.0:* users:(("docker-proxy",pid=15626,fd=4))
tcp LISTEN 0 4096 [::]:9999 [::]:* users:(("docker-proxy",pid=15889,fd=4))
tcp LISTEN 0 4096 [::]:8888 [::]:* users:(("docker-proxy",pid=15639,fd=4))
And because they are just processes we can even list them using ps -fC docker-proxy.
┌──(ales㉿kali)-[~]
└─$ ps -fC docker-proxy
UID PID PPID C STIME TTY TIME CMD
root 15626 825 0 Aug03 ? 00:00:00 /usr/sbin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 8888 -container-ip 172.17.0.3 -container-port 80
root 15639 825 0 Aug03 ? 00:00:00 /usr/sbin/docker-proxy -proto tcp -host-ip :: -host-port 8888 -container-ip 172.17.0.3 -container-port 80
root 15882 825 0 Aug03 ? 00:00:00 /usr/sbin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 9999 -container-ip 172.17.0.4 -container-port 80
root 15889 825 0 Aug03 ? 00:00:00 /usr/sbin/docker-proxy -proto tcp -host-ip :: -host-port 9999 -container-ip 172.17.0.4 -container-port 80
From outside
This will be quite similar to the technique we’ve just discussed.
But before we start let’s first think what we want to do. Basically we want to expose a port on our host and once outside world connects to that port we want to navigate it to the container internal IP .
How can we do that? Yup iptables, but this time we are interested in the PREROUTING chain inside NAT table.
The PREROUTING chain in the NAT table is used to modify packets as they arrive at the network interface, before any routing decisions are made. This makes it an ideal candidate for altering packet destinations.
┌──(ales㉿kali)-[~]
└─$ sudo iptables -L -t nat
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
DOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
Chain INPUT (policy ACCEPT)
target prot opt source destination
...
Chain DOCKER (2 references)
target prot opt source destination
RETURN all -- anywhere anywhere
RETURN all -- anywhere anywhere
DNAT tcp -- anywhere anywhere tcp dpt:8888 to:172.17.0.3:80
DNAT tcp -- anywhere anywhere tcp dpt:9999 to:172.17.0.4:80
So from the output above we can see that Docker creates a new chain which gets added to PREROUTING chain. Inside this chain we see that if TCP traffic comes to the published port it should forward traffic to containers internal IP addresses.
And that is it. A little iptables magic always helps.
How does container communicate with outside world?
So what happens when a containerized process needs to call an external service?
Lets first check ip route to display IP routing table of a system.
┌──(ales㉿kali)-[~]
└─$ docker exec -it container-a bash
root@4a218a420594:/# ip route
default via 172.17.0.1 dev eth0
172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.3
Default indicates default route, which is used for all traffic that doesn’t match any specific route in the routing table. In this case it will be routed through Docker bridge (172.17.0.1) using eth0 interface.
Once it reaches to host it will again need to figure out where to go. Lets recheck ip route on host as well:
┌──(ales㉿kali)-[~]
└─$ ip route
default via 192.168.64.1 dev eth0
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
172.23.0.0/16 dev br-b52ba1fca3c3 proto kernel scope link src 172.23.0.1 linkdown
192.168.64.0/24 dev eth0 proto kernel scope link src 192.168.64.2
As we might have thought it will be routed to eth0.
For this to work we also need to enable IP forwarding on our host, because packets will have to jump to a different interface (bridge0 -> eth0).
It turns out Docker does this for us.
┌──(ales㉿kali)-[~]
└─$ sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 1
And then the packet finally reaches its destination, and we get that juicy data back, right? Not quite.
Docker needs to do a bit more.
Imagine the packet reaches the external service. The problem with the current setup is that the source IP will still be set to the internal IP of our container, which in this case is 172.17.0.3.
So, the response would try to reach 172.17.0.3 directly, which isn’t routable on the internet.
How do we fix this? Yup iptables again. But this time we are interested in
POSTROUTING chain inside NAT table, which is used to modify
packets after they have been routed, just before they leave the system.
┌──(ales㉿kali)-[~]
└─$ sudo iptables -L -t nat
...
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 172.17.0.0/16 anywhere
MASQUERADE tcp -- 172.17.0.3 172.17.0.3 tcp dpt:http
MASQUERADE tcp -- 172.17.0.4 172.17.0.4 tcp dpt:http
The MASQUERADE rules ensure that the source IP address of these packets is replaced with the IP address of the outgoing network interface. This makes all outbound traffic appear as if it originates from the same public IP address.
So, once the packet reaches the destination, its source IP will be set to our outgoing network interface IP address. This way, when the external service replies, the response will be correctly routed back to the container through the host.
And we have a working connection!
Conclusion
Before I started writing this post, I thought I would also demonstrate how to mimic Docker networking using Linux kernel tools. However, I realized that this post is already quite detailed. Maybe I’ll create a follow-up post to cover that topic.
I hope this post made Docker networking a bit clearer. What I’ve
described is the default scenario when we use bridge network.
For example we could just reuse the host network namespace
using the --net=host flag.